THE FRIENDLY ML ALGORITHM
The K-Nearest Neighbors is a simple, easy to implement, and very versatile algorithm and for anyone new to the machine learning field, it’s one of the building blocks. In this article, I’ll be explaining the theory behind the algorithm and how to implement it in the Python programming language.
PREREQUISITES
Knowledge of the python programming language
Knowledge of Exploratory data of analysis
THE KNN THEORY
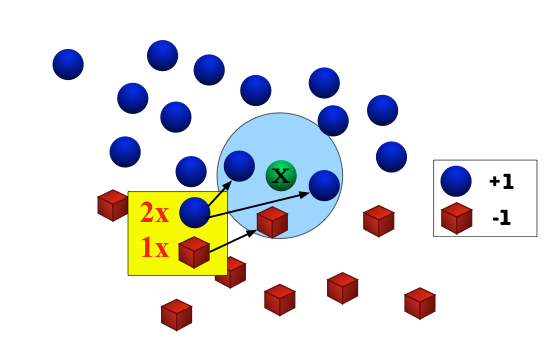
The K Nearest Neighbors algorithm is a classification and regression algorithm (commonly used for classification) that operates on a simple theory. If we had a bowl of red and blue pebbles separated by a line with the reds on the left and the blue ones on the right, and then we decide to shut our eyes and pick a color from any side we know to guess the color, guessing the right color would be pretty easy since we know that they are both separated by the line, so if we pick from the right side, we are sure to get a red ball and vice versa. Now, imagine we have another bowl of pebbles but this time the pebbles are mixed in such a way that no line is separating the regions bounded by the colors, and traces of the other colors are on the other sides. Conducting the pick and guess process, the probability that a red is selected on the right side is still very high although a blue could be picked thus reducing the probability of picking a red on the right.
As seen in the analogy, the side from which a pebble is selected is a factor in the classification process. Picking from the boundaries also decreases the probability of a color being predicted true since the colors meet at a boundary. This is similar to how the KNN algorithm works. From the analogy, each pebble is a data point, the selected pebble is the data point we are trying to classify, and your brain is the algorithm predicting the color of the selected pebble. In summary, the KNN algorithm classifies by calculating the mean distance of a point to other data points
THE K-NEAREST NEIGHBORS ALGORITHM IN PYTHON

Where K is the number of neighbors a data point has, the K nearest neighbor’s algorithm classifies by calculating the distance of the selected or new data point (x) to the other points on the data, sorts by increasing the distance of the data points from x and then predicts the majority of the k closest points. Choosing the best number of neighbors (k) is very important to be able to maximize prediction accuracy
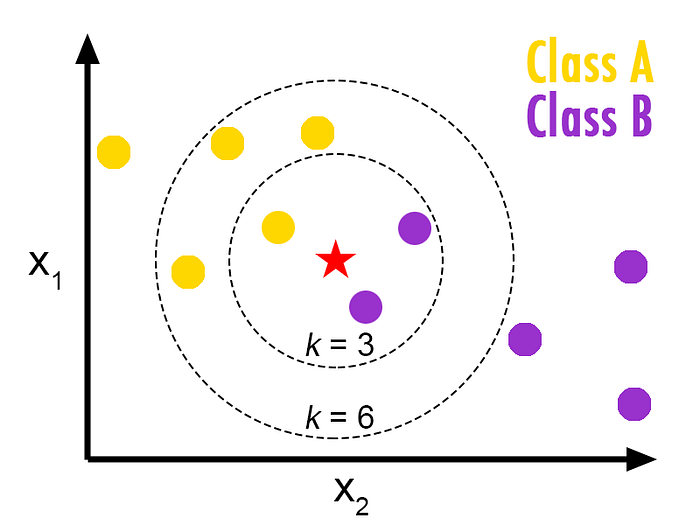
As shown in the image, a K value of 3 increases the probability of the new point being a member of class B, and choosing the value of 6 gives class A the upper hand of claiming the point.
The algorithm might not yield the best results on large data
Scaling is very important since the algorithm predicts by measuring the distance between datapoints
KNN does not work well on categorical data
The K nearest neighbors algorithm is a member of the neighbors family of the sci-kit learn library. The syntax for importing and initializing is as thus:
from sklearn.neighbors import KNeighborsClassifiermy_model = KNeighborsClassifiers(n_neighbors=5)
FEATURES NORMALIZATION
To reduce variance and avoid data overfitting, feature normalization is important. Normalization(scaling) is a technique used to resize values of different scales s to a common range. Normalization(scaling) is usually carried out for algorithms that calculate distances between data points. The common normalization technique used with the KNN algorithm is the Standard scaling technique which also comes built-in with the preprocessing class of the sci-kit learn library. We will be focusing on standard scaling in this post, if you’d love to know more about other scaling techniques, here is a link you could check out. Standard normalization (scaling) is done by dividing the difference between the feature and the mean (average) by the standard deviation.
Mathematically standardization is given as;
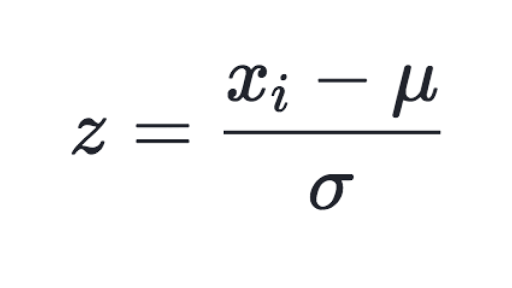
Where the numerator is the difference between the value and the mean and the denominator is the standard deviation. After scaling, the mean and variance of the data are reduced to 0 and 1 respectively. Scikit learn carries out standard scaling for us so we don't have to do it manually. Here’s how
Features_to_scale = df[[‘features to perform standardscaling on’]]# targets are not to be scaledFrom sklearn. Preprocessing import standardscalerScaler = standardscaler()Scaler.fit(Features_to_scale)Scaled_version = scaler.transform(Features_to_scale)
we transform the scaled features to standardize the data by centering and scaling them.
After the transformation process, the output is a NumPy array containing the normalized values. We head on to using pandas to convert to a data frame using the pandas’ data frame method which takes in the array, a list of feature names, and some other arguments.
Scaled_dataframe = pandas.Dataframe(scaled_version,Features_to_scale.columns)# The Features_to_scale.columns argument simply gets the list of the original feature names for use
Then, we split into training and testing data to feed to our algorithm;
from sklearn.cross_validation import train_test_splitX = scaled_dataframe[[“Feature columns”]]Y = target_classX_train ,X_test, y_train, Y_test =train_test_split(x,y,test_size=0.3)
Now that we have our training and testing data, it’s time
to import, instantiate, fit and predict (The machine learning workflow in python) know more about it here
We import the KNN algorithm
from sklearn.neighbors import KNeighborsClassifierThen we initialize. The KNeighborsClassifiers algorithm takes in a bunch of parameters but the most important is the n_neighbors which stands for the number of neighbors (k).
Then, we fit out training data to the model
my_model.fit(X_train, y_train)Now we can get predictions off our data;
prediction = my_model.predict (X_test)`
Been a pretty nice time getting into your brains, till I repeat this feat, the same blog, next time 🐱💻😁